

米国勢調査局の差分プライバシーレポート/プライバシー強化暗号による差分プライバシーの補完
米国勢調査局の差分プライバシーレポート/プライバシー強化暗号による差分プライバシーの補完
LayerX Labs Newsletter for Biz (2021/10/27-11/02) Issue #129

今週の注目トピック
Takahiro Hatajima(@th_sat)より
米国勢調査局が発表したレポート「2020年国勢調査に向けた情報開示の回避」の概要を紹介します。
あわせて、プライバシー強化暗号による差分プライバシーの補完について紹介します。
Section1: PickUp
●米国勢調査局、2020年の国勢調査における差分プライバシー使用について説明するレポート「2020年国勢調査に向けた情報開示の回避」を公開
米国の国勢調査における差分プライバシー適用について、これまでに数回にわたってニュースレターで紹介してきたが、このたび2020年の国勢調査における差分プライバシー使用について説明するレポートが正式に公開されたため、その概要を紹介したい。
米国で10年ごとに行われる国勢調査は、議会の割り当てを決定し、各州の区割りにも利用され、何千億ドルもの連邦資金の配分にも影響を与える重要な調査である。一方で、国勢調査局等が行った調査によれば、潜在的回答者が調査に参加したくない理由として、プライバシーや機密性に関する懸念が最もよく挙げられることがわかっている。国勢調査局にとっての課題は、これらのデータを収集・報告する必要性と、守秘義務を守るという法律上の義務とのバランスをとることだ。そのため、公表された集計結果の開示から情報を保護すべく、開示回避手続き(データの機密性を保護するデータ加工技術)を採用している。トップコーディングやボトムコーディングといった手法以外で代表的なものが、1990年の調査から使われている「データ・スワッピング」だ。データ・スワッピングでは、特定の世帯の記録を近隣地域の類似した特徴を持つ世帯の記録と交換することによって、データに「ノイズ」を注入する。ここで課題とされるのが、スワッピングの具体的な方法について情報を公開しておらず透明性がないため、データ利用者はこれらの保護が公表データに与える影響を評価することができない点である。
さらに課題とされるのが、コンピュータ技術の進歩と、商業利用可能なデータベースの急速な増加により、データベースの再構築や再識別攻撃に対してますます脆弱になっているという点だ。外部の人間が、公開されている表の情報を組み合わせることで、氏名・住所が記載されていない元の国勢調査の回答を「再構築」したり、国勢調査の回答と共通する変数について「外部のデータベースに連結・リンク」することによって国勢調査の回答者個人に関する機密情報を推測したりすることが可能となっている。
例えば、2018年に国勢調査局は、2010年の国勢調査から公開された表をもとに、データベースの再構築をシミュレーションする実験を行った。実験の結果、米国人口の46%に当たる1億4400万人については、地理的な場所(国勢調査ブロック)・性別・年齢・人種・民族が国勢調査の回答と一致したという。さらには、外部データベースの名前と住所を再構成された記録にリンクすることによって、1億3800万件のリンクされたレコードのうち38%で再識別ができてしまった。
こうした「連結」によって、攻撃者が、人種や民族といった外部データベースにはまだ存在していない個人の機密情報・センシティブな情報を推測することができてしまう。このように、国勢調査データをリバースエンジニアリングしようとする人々による再構成や再識別の成功を防ぐことが必要だ。特に、国家機関(例:外国政府)・企業・サイバー犯罪者などによる試みは、再構築・再識別の攻撃が成功したことを公に発表することはないと考えられるため警戒が不可欠である。
従来の情報開示回避方法には、潜在的なデータベース再構築や再識別攻撃を防御するようには設計されていなかったため、国勢調査局は「公開する情報を大幅に減らすか」「機密保護のために最新のアプローチを採用するか」を迫られ、後者を選択した。2020年の国勢調査のデータについて、国勢調査局は、「差分プライバシー」という比較的新しい情報開示回避の枠組みを適用した。
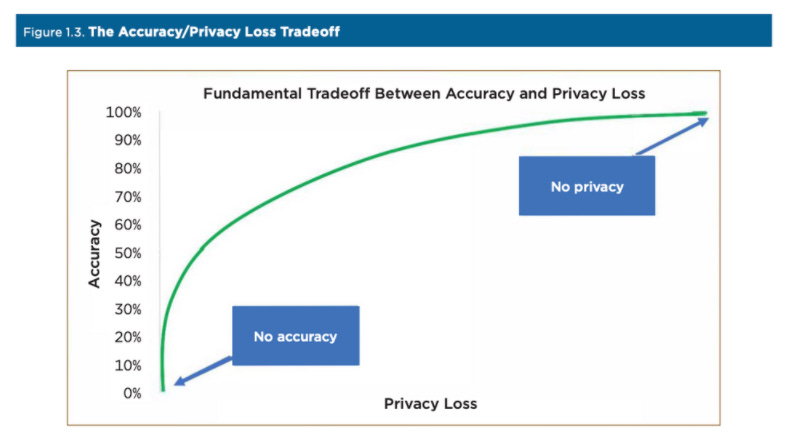
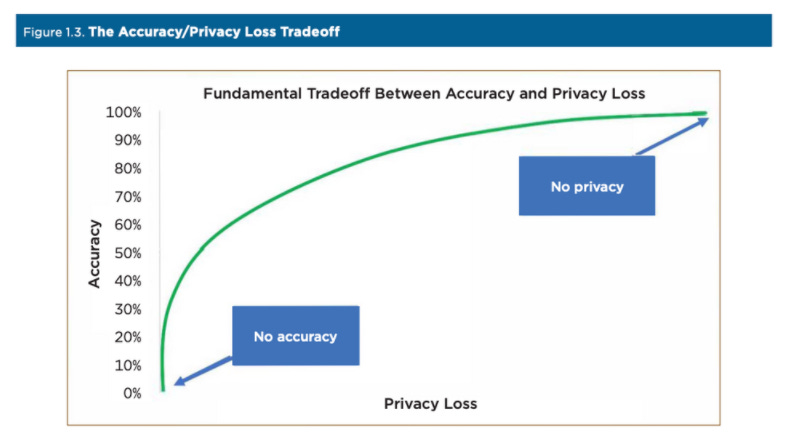
差分プライバシーの目的は、統計的有用性を維持したまま、(データベース内の)個人または個人の小グループの存在の有無を不明瞭にすることだ。差分プライバシーは、収集したデータに「ノイズ」を加えることで機能する。たとえばテレビ画面において、ノイズがあると、個々の人物を正しく識別できるリスクが減るが、ズームアウトしても全体像は維持される。
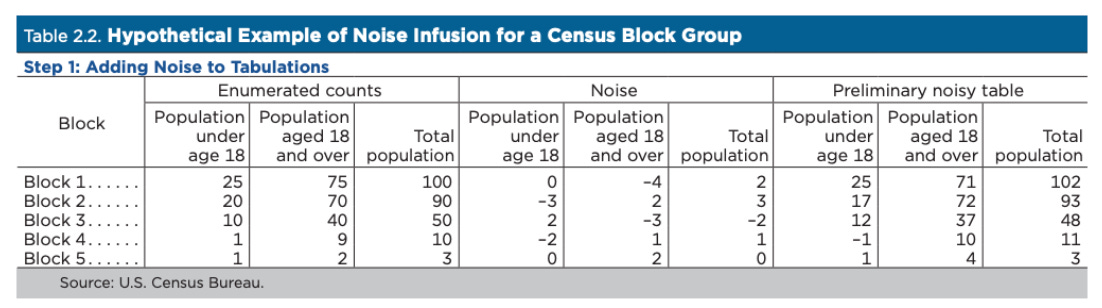
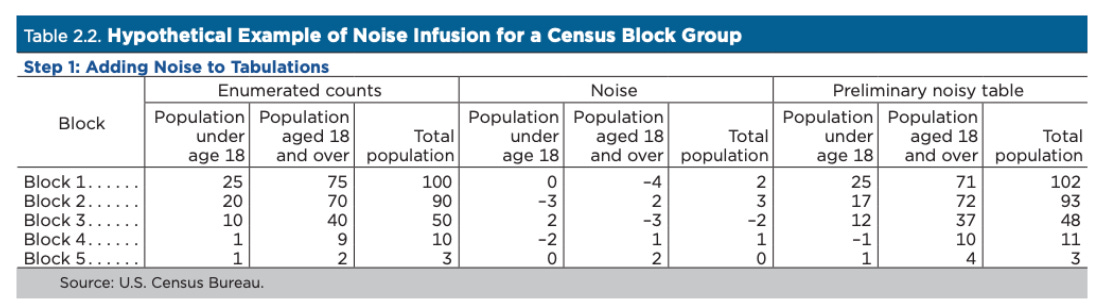
より多くのノイズを加えることで、機密性の保護は高まるが、データの精度は低下する。差分プライバシーでは、このトレードオフを定量化することができるため、開示基準設定の透明性を確保することができる。差分プライバシーは、数学的には、単純な集計から複雑な回帰まで、データ分析の結果が、データセットに個人が含まれていてもいなくても、ほぼ同じ確率で得られるという枠組みである。ある個人がデータセットに含まれているかどうかにかかわらず、分析結果が本質的に同じであれば、その個人の機密情報は保護されることになる。
国勢調査局が採用した差分プライバシーは、いくつかの点で、教科書的なアプローチと違う点がある。①まず、国勢調査では、機密性とデータの正確さのバランスをとる必要があるため、一部のセルに大量のノイズを加えると、データの利用に支障をきたす可能性がある。そのため、国勢調査局は、Zero-Concentrated Differential Privacy(zCDP)と呼ばれる枠組みを導入した。これにより、同じレベルのプライバシーロスバジェットであれば、純粋な差分プライバシーに比べて、異常に大きなノイズが混入する確率が低くできる。②2点目の特徴として、ノイズを加えずに集計したままのデータである「不変量」が含まれている。具体的には、各州の総人口や、各国勢調査ブロックの住宅総戸数などだ。③さらに、これら不変量に加えて、「人口および住宅数は整数でなければならず負数であってはならない」「選挙権年齢人口は総人口を超えてはならない」「テーブル内、テーブル間、および地域間でカウントが一貫していること」といった追加制約を区割りデータセットに適用している。
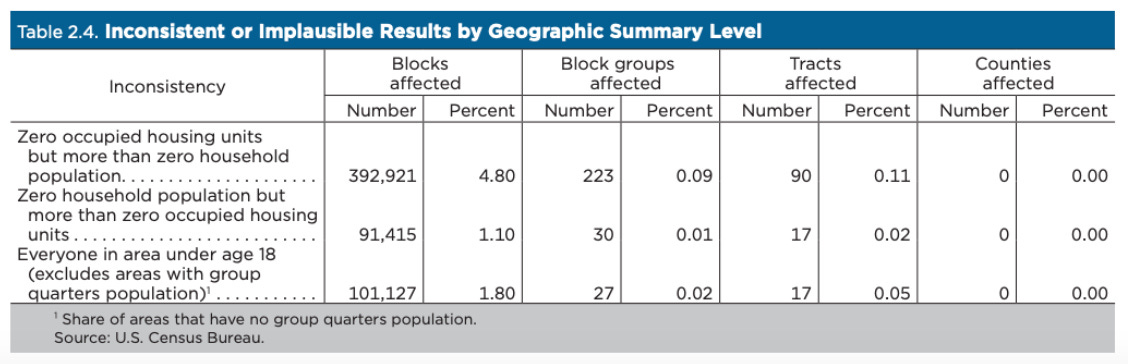
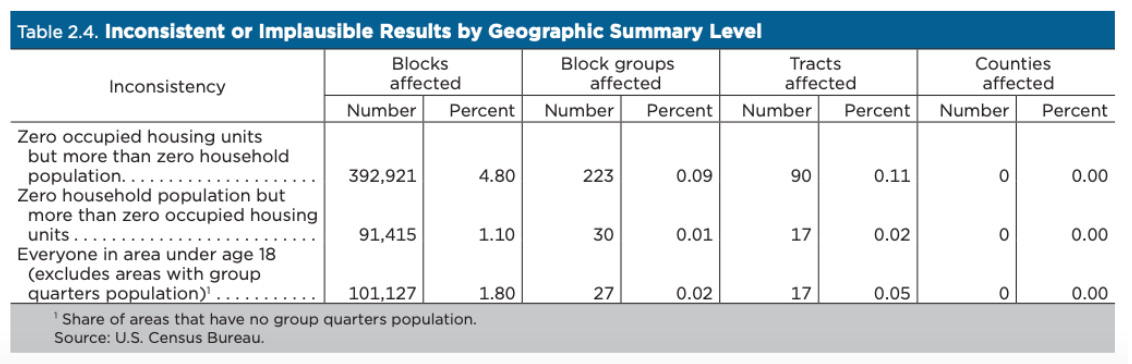
なお、セルに追加されるノイズの量は、そのセルに含まれる人口の大きさとは無関係である。例えば、人口10万人の地域に5人が加わる可能性と、100人が加わる可能性は同じである。つまり、絶対誤差はどちらのエリアでも同じだが、人口の少ないセルに加わったノイズは、基礎となる人口(分母)が少ないため、相対誤差が大きくなる。このため、ノイズを注入することによって、地区再編成のデータにありえない結果が出る可能性がある他、また、数学的に不可能な統計データも含まれている可能性がある。このような矛盾したありえない結果は、人口が非常に少ない地域によく見られるが、ブロックグループの約0.1%に過ぎない。そのため、データ利用者は、ブロックレベルのデータをより人口の多い地域にまとめることを推奨されている。
商用データベースやオープンデータの急激な増加に伴い、個人を特定する情報を含まないはずの統計調査などのデータが、意図しない形で、外部データとの連結などを通じて、個人を特定することにつながるケースが、今後増える可能性がある。そうした場合のソリューションの1つと考えられる「差分プライバシー」について、更なる取り組みの進展に注視したい。(文責・畑島)
●差分プライバシーを補完するPrivacy-enhancing cryptography(PEC)
プライバシーを保護しつつ、データの有用性を維持するために期待されるPrivacy-enhancing cryptographyの様々な技術と差分プライバシーの組み合わせについて、アメリカ国立標準技術研究所(NIST)に掲載されたブログから具体的な手法を紹介する。
Privacy-enhancing cryptographyは、複数の当事者間でのデータ共有を避けることができるため、複数の当事者や対話型シナリオにおける課題解決に適している。
また、差分プライバシーと組み合わせることで、プライバシー保護の方法で処理できる問題の範囲を広げることができる。
複数のデータセットにおけるデータプライバシーの保護について、より具体的な例から理解を深める。
AliceはHA病院のデータスチュワード(データを管理・保護する人)で、患者の医療記録のデータベースに責任を持っている。
同様に、Bobは別の病院HBでデータスチュワードを務めている。AliceとBobは、患者の年齢と診断結果の相関関係について、Ryaが研究中であることを知った。
この研究は、より良い医療行為を導き出すための有益な洞察を提供することができるので、AliceとBobはRyaを助けたいが、プライバシーに関する制約があり、データベースを共有することができない。
Ryaは、ある症状Xと診断された患者の数を、年齢層別に知りたいと考えているとする。差分プライバシーにより、Ryaは2つの病院のそれぞれから、プライバシーを守るためにノイズを加えて調整した近似結果を得ることができる。
しかし、別々の結果として受け取りが限定されることには、欠点がある。
(1) 2つの結果を組み合わせる際に、重複している可能性があるため、Ryaは必要な修正を行うことができない。
(2) 個々の回答のペアは、Ryaの目的とは関係のない病院の違いに関する情報を漏らす。
上記のシナリオとは対照的に、Privacy-enhancing cryptography ではRyaがAlice,Bobと対話して、重複データに関して修正された結果を得ることができる。
これは、AliceとBobが自分たちの間でデータを共有することなく、また、Ryaが意図した出力以上のことを知ることなく行われる。
このようにPrivacy-enhancing cryptographyは、差分プライバシー技術と組み合わせることで、プライバシーと有用性の最適なトレードオフを実現する。
表1は、Privacy-enhancing cryptographyを使用しない場合に、どのようなエラーが発生するかを示している。
2つの相関するカウントの合計に誤差が生じており、2つのセットの組合わせにおける真のカウントを過大評価している。
このようなエラー(例では25%以上の割合)は、結果の実用性を大きく妨げる可能性がある。
表1:診断名Xの患者数の尺度(N)
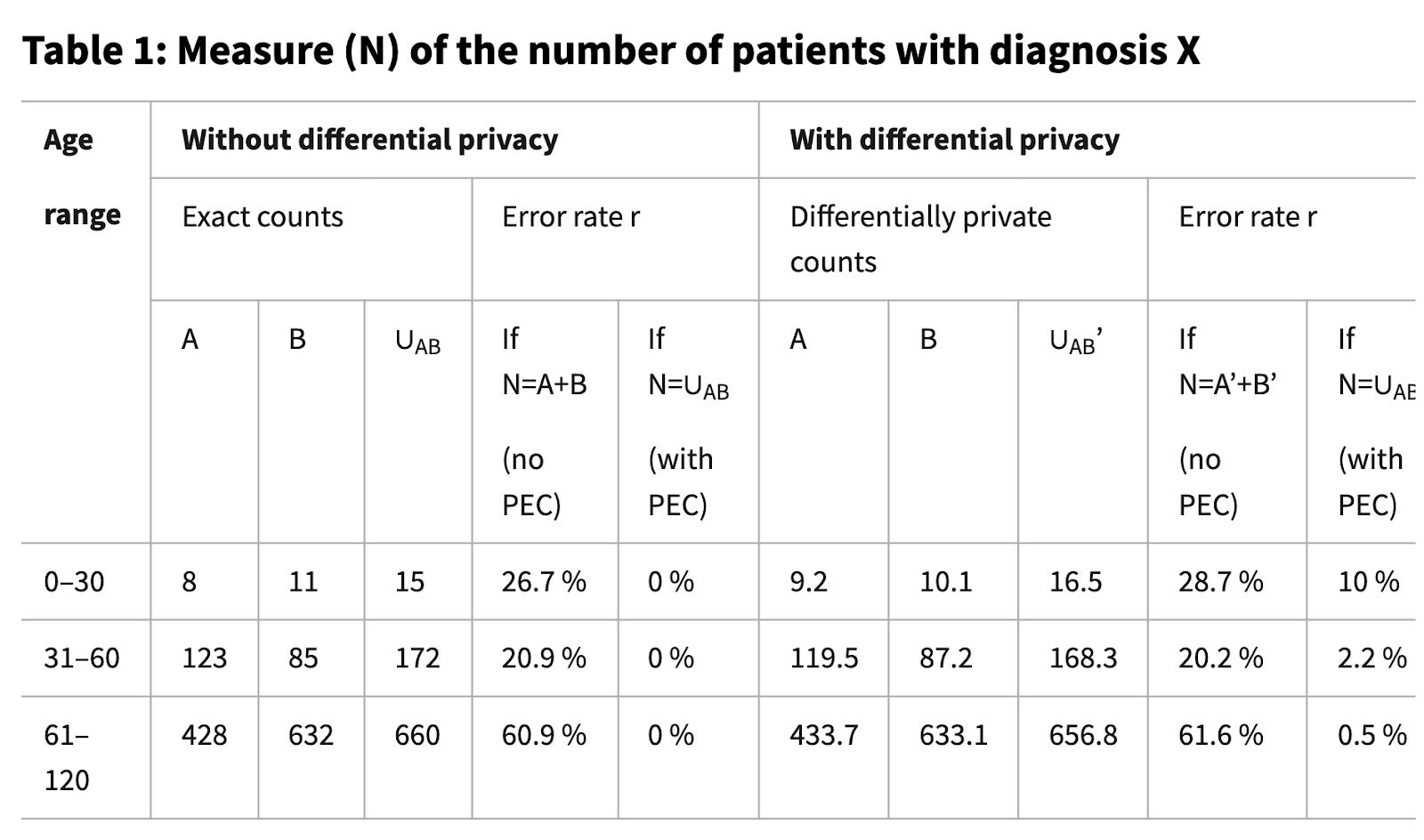
出典:Privacy-Enhancing Cryptography to Complement Differential Privacy, Table1
A(病院HAでのカウント);B(病院HBでのカウント);∪AB(病院HAとHBの組合わせでのカウント);A';B';∪AB'(A、B、∪ABの差分非公開バージョン);r = N/∪AB - 1
このように差分プライバシー技術は、クエリの正確な結果にノイズを加えることで、プライバシーの損失を抑えつつ、データベースへの関連するクエリに対して有用な回答を得ることができる。
次の段落では,安全なマルチパーティ計算(SMPC),秘密集合交差(PSI),秘密情報検索(PIR),ゼロ知識証明(ZKP),完全同型暗号(FHE)という5つのPrivacy-enhancing cryptographyについて検討する。
先程の例と同様のケースを想定し、複数のデータベースを扱わなければならない、Ryaからのプライバシー制限を考慮しなければならない、一部の当事者が誤動作しても正しさを保証しなければならない、といった設定を考える。
SMPC。SMPC(Secure Multiparty Computation)では(例えばYaoやGMWプロトコル)、Ryaは実際にデータベースを結合することなく、AliceとBobの結合されたデータベースで計算された統計量を知ることができます。AliceとBobはお互いのデータを見ることはなく、Ryaは得られた(差分的に秘密の)統計量から推測されること以外、データベースについて何も知ることはできない(図1参照)。
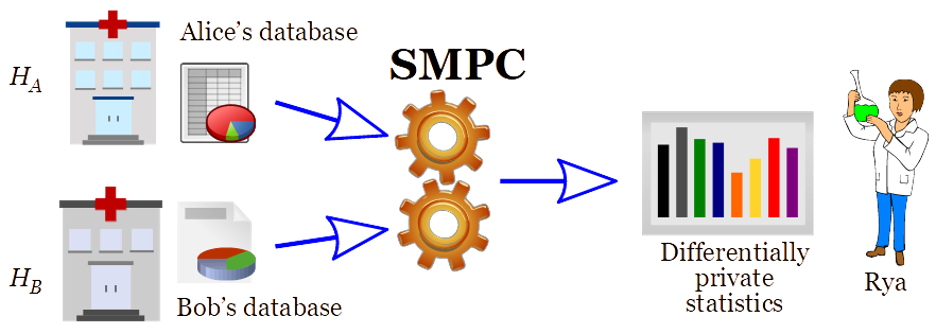
Figure 1: “Secure computation” of differentially private statistics from combined databases
図1に示したように、SMPCと差分プライバシーを組み合わせて適用することで、「セントラル(グローバル)差分プライバシー」や、キュレーターがデータを組み合わせる「ローカル差分プライバシー」よりも安全な代替手段を構成するが、プライバシー侵害の対象にもなる。
セントラルDPでは、ハッキングされる可能性のあるキュレーターが複数の病院のデータの管理者としての役割を果たし、DP方式で問い合わせに答えられるようにする必要があるため、セキュリティ面で妥協している。
ローカルDPは、プライバシーと精度のトレードオフの関係にあり、各病院からキュレーターに送られるデータがDPで保護されていることを要求することで、キュレーターがハッキングされるという予測可能なケースを軽減する。
差分プライバシーが適用されたSMPCは、可能な限り最高の精度を提供し(セントラルDPと同様)、キュレーターのハッキングによるリークの可能性を回避する(セントラルDPとローカルDPの両方)という、両方の長所を兼ね備えている。
次にプライベートセットインターセクション(PSI)について紹介する。PSI(MatchmakingやOblivious Switchingプロトコルなど)では、AliceとBobは、他の患者に関する情報を共有することなく、それぞれのデータベースに共通する患者のセットを知ることができる。
当然のことながら、この交点は秘密にしておくべき機密情報と考えられる。
PSI cardinality(カラムに含まれる値の種類の濃度)と呼ばれるバリアントを使用すると、集合自体を漏らすことなく、共通の患者が何人いるかなどの統計を計算することができる(図3参照)。

Figure 3: Private set intersection cardinality (PSI#) of patients across two hospitals
交差点のcardinalityでさえも機密情報である可能性があるため、得られる統計値自体が、差別的なプライバシー保護の対象となり得る。
別の角度から見ると、この統計値は、外部の研究者からの後続の問い合わせに対して、プライバシー保護レベルの差をどのようにパラメータ化するかを決定するために、病院にとっても有用である。
これにより、後にRyaが両方の病院に個別に問い合わせを行うような場合に、プライバシーや精度が向上する可能性がある。
プライベート情報検索(PIR)では、Ryaは、Aliceのデータベースに送られたクエリの結果を知ることができるが、Aliceは何がクエリされたかを知ることはできない(図4参照)。
表1の例を思い出してみると、Ryaは、Aliceが質問された年齢層を知らなくても、診断名がXで年齢層が31-60のHAの患者数(A=123)の差分私的近似値(A'=119.5)を知ることができる。

Figure 4: Private information retrieval (PIR) of a differentially private statistic
ZKP(Zero-knowledge Proofs)とは、何らかの方法で「コミット」されたデータ(例えば、暗号化されたデータベースを公開するなど)について、実際のデータを公開することなく証明することができる手法である。
これにより、データがコミットされた後、データベースの所有者は、ある問い合わせに対する返答が、変更されていないデータに正しく関連していることを証明することができる。
これは、プライバシーを保護しながら説明責任を果たすことができる優れたツールであり、特にいわゆる悪意のあるモデルにおいて、他のPEC技術(SMPC、PSI、PIRなど)を可能にするために使用することができる。
例えば、AliceがRyaに対して、ある答えが適切な差分プライバシー保護を満たしていること、すなわち、元の秘密データベースに関して正しいノイズ付加の結果であることを証明するために使用することができる(図5参照)
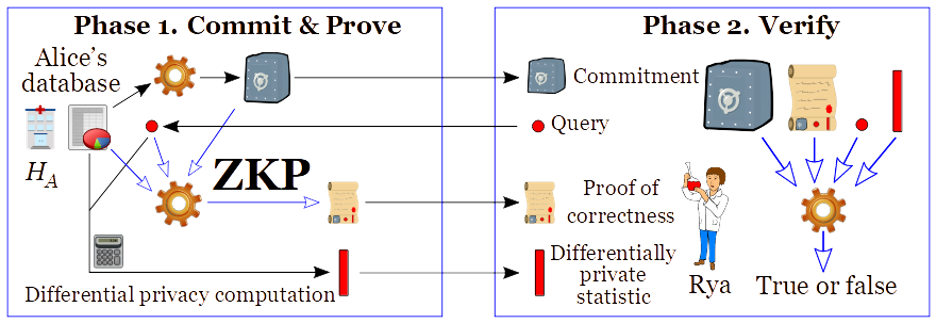
Figure 5: Differentially private answer, with a zero-knowledge proof (ZKP) of correctness
完全準同型暗号(FHE)は、暗号化されたデータを、秘密鍵を知らずに計算することができる。
概念的には、Ryaは意図したクエリを暗号化し、それを1つまたは複数の病院に送信し、病院に暗号化されたクエリを暗号化されたDPで保護された結果に変換させ、後でRyaがそれを復号することができる(図6参照)。
この計算は、病院間で順次行うことができ、それぞれの新しい変換は、Ryaが復号する最終段階まで暗号化されたままとなる。
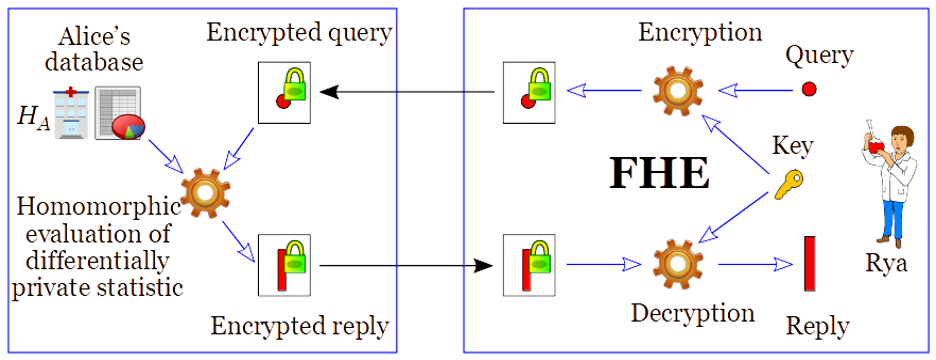
Figure 6: Using FHE for private computation of differential private statistics
FHE の欠点は,他のソリューションに比べて計算量が多いことだが、実用的なアプリケーションも生まれており、この分野は急速に進歩している。
Privacy-enhancing cryptographyと差分プライバシーの役割は大きく異なるが、補完的な関係にあり、どちらの技術も有用な統計の計算を可能にしながらプライバシーを保護するために適用できる。
Privacy-enhancing cryptographyと差分プライバシーをうまく活用し、データのプライバシーを保護しながら、データの利活用がさらに推進されることが期待される。(文責:野畑)
LayerX Labsでは、次世代プライバシー保護・セキュリティ技術Anonifyの正式提供に向けトライアルパートナーの募集を開始、合わせて公式ウェブサイトを公開しました。

「Anonify」の公式ウェブサイトはこちら
「Anonify for Insurance」ホワイトペーパーはこちら
LayerXではエンタープライズ向けブロックチェーン基盤を基本設計、プライバシーの観点から比較したレポートを執筆し、公開しています。
基本編のダウンロードはこちら
プライバシー編ダウンロードはこちら
Section2: ListUp
1. プライバシー・セキュリティ
●改正個人情報保護法で新設される「仮名加工情報」とは?
https://news.mynavi.jp/article/20211029-2172697/
●令和3年個人情報保護法改正について
https://www.icr.co.jp/newsletter/wtr391-20211028-muramatsu.html
●改正個人情報保護法への対応、金融・医療で進む - PwC調査(2021年10月29日)https://news.biglobe.ne.jp/it/1029/mnn_211029_0175059679.html
●「個人情報の保護に関する法律についてのガイドライン(行政機関等編)を定める告示(案)」に関する意見募集について
https://public-comment.e-gov.go.jp/servlet/Public?CLASSNAME=PCMMSTDETAIL&id=240000074&Mode=0
●第190回 個人情報保護委員会 |個人情報保護委員会
令和3年度上半期における個人情報保護委員会の活動実績について
令和3年改正個人情報保護法 公的部門ガイドライン案について
LINE株式会社における改善状況の概要及び同社等に対する対応方針
https://www.ppc.go.jp/aboutus/minutes/2021/211029/
●Facebook、顔認識の利用を中止へ プライバシーに配慮: 日本経済新聞
https://www.nikkei.com/article/DGXZQOGN030DF0T01C21A1000000/
https://www.reuters.com/technology/facebook-will-shut-down-facial-recognition-system-2021-11-02/
●顔認識アプリのClearview AI、オーストラリアでプライバシー法違反と判断される
https://japan.cnet.com/article/35178964/
●プライバシーガバナンスに関するアンケート結果(速報版)を公開しました (METI/経済産業省)
https://www.meti.go.jp/press/2021/10/20211018002/20211018002.html
●SaaS利用者/事業者が知っておくべきクラウドセキュリティの確かめ方と高め方 —第6回クラウドサービスにおける個人情報の考え方 - サインのリ・デザイン
https://www.cloudsign.jp/media/20211103-saassecurity6/
●ガートナーが予想する今後数年のサイバーセキュリティ
https://japan.zdnet.com/article/35178572/
●マネーロンダリングなどの不正利用を防ぐインテルCPUのセキュリティ技術「SGX」
https://pc.watch.impress.co.jp/docs/topic/special/1354641.html
●電通らがTwitterとデータクリーンルーム構築、クッキーを使わずにデータ連携
https://active.nikkeibp.co.jp/atcl/act/19/00012/102900598/
●米国国勢調査における差分プライバシー適用で「現実世界には存在するのに、少なくとも紙の上では、人や居住している家が消えてしまった」として再び話題に
●差分プライベートクラスタリングについて、Google AIブログ
https://ai.googleblog.com/2021/10/practical-differentially-private.html
●スペインのデータ保護当局(AEPD)による、差分プライバシーモデルの適切な展開とメリットに関するブログ
「匿名化にまつわる誤解」「プライバシー対策としてのK-匿名化」「プライバシーエンジニアリング」の紹介も
●Microsoftによる差分プライバシー紹介ページ
「Differential Privacy for Everyone」PDF(6枚もの)をダウンロード
https://docs.microsoft.com/ja-jp/viva/insights/Privacy/differential-privacy
●GoogleによるTensorFlow Federated(TFF)を用いた連合学習・分析ワークショップ
トピックの一つとして、現実のシステム制約の中で、差分プライバシーを用いた連合学習モデルの学習についても紹介。
https://events.withgoogle.com/federated-learning-workshop-using-tensorflow-federated/#content
●ヘルスケアむけ合成データレプリカ
https://github.com/Jeremy-Harper/Synthetic-Data-Replica-for-Healthcare
●合成データがメタバースの構築にどう役立つか
https://sharecaster.com/how-synthetic-data-will-help-build-out-the-metaverse/
2. 中銀デジタル通貨
●J.P. MorganとOliver Wymanによる、クロスボーダーホールセール決済におけるmCBDCネットワークの可能性についてのレポート。
本格的なmCBDCネットワークによるクロスボーダー決済を80%削減できる可能性
3. 今週のLayerX
●不動産ファンド2号及び3号案件の運用受託開始のお知らせ|三井物産デジタル・アセットマネジメント株式会社
運用資産総額は50億円を突破、デジタル証券ファンドの普及に向けて加速
https://prtimes.jp/main/html/rd/p/000000007.000056997.html
●0→1環境での意思決定が「再現性」をつくる。僕がマーケターにスタートアップへのJOINを勧める理由
https://note.com/uchiken_lx/n/n016b4ef08b6d
●プロダクトフィードバックループを回すのはCSの役割|かじ|note
フィードバックを集め続けるための工夫について明かされています!
https://note.com/kajisan_startup/n/n07171e08fcee
●11/11に開催するオンラインイベント「コーポレート DX DAY」では、来年1月に電子帳簿保存法の改正法施行が迫るこのタイミングで、コーポレートDXを推進するためのヒントをご紹介します!
https://prtimes.jp/main/html/rd/p/000000089.000036528.html
●LayerXのピポットの背景・経緯・その後の歩みについて、日経産業新聞さんに丁寧な記事にしていただきました!
https://www.nikkei.com/article/DGXZQOUC045S50U1A001C2000000/
●LayerXのCompany Deckが公開されました!
取り組んでいる3つの事業、今後の展望、そして「今」むきあっている実現する上での課題について整理しています。
●LayerXの採用ページ(Entrance Book)が、大幅アップデートされました!
https://layerx.notion.site/LayerX-5a5845c2dc5241518eb7f3bf21433793
製品紹介・デモのご依頼に向けたお問い合わせは、こちらの「お問い合わせフォーム」よりお願いします
Disclaimers
This newsletter is not financial advice. So do your own research and due diligence.
