

JP Morganの合成データ活用ユースケース/合成データの利用における留意点
JP Morganの合成データ活用ユースケース/合成データの利用における留意点
LayerX Labs Newsletter for Biz (2021/10/13-10/19) Issue #127

今週の注目トピック
Takahiro Hatajima(@th_sat)より
JP Morganの合成データ活用ユースケースについて紹介します。
あわせて、合成データの利用における留意点について紹介しています。
Section1: PickUp
●JP Morganの考える「銀行業務デジタル化における合成データ活用」の姿
JP MorganのTechブログ9月号において、「Synthetic Data for Real Insights」と題する記事が掲載された。関連するJP Morganの合成データ活用ユースケースとあわせて、概要を紹介したい。
金融サービスでは、非常に複雑で多様性に富んだ膨大な量のデータが生成される。しかし、これらのデータセットは、規制上の要件やビジネス上の必要性など、さまざまな理由で組織内のサイロに保存されていることが多い。その結果、様々なビジネスライン内でのデータ共有や、組織外(研究コミュニティなど)でのデータ共有は非常に限られたものとなっている。(出所:JP Morgan Chase, “Generating Synthetic Data in Finance: Opportunities, Challenges and Pitfalls”)
AIモデルがビジネスシナリオにおける人間の行動を効果的に実証するためには、現実を代表する大量のデータを用いて学習する必要がある。金融サービス業界では、非常に有益なデータが大量に生成されているものの、実際のデータはプライバシーや法的な許可、容量や表現、意味に関する技術的な側面などの面でアクセス困難・利用できないことが多いため、研究者や開発者にとって根本的な課題となっている。
データ漏洩やプライバシー侵害のリスクを回避しながら、社内外のデータプロジェクトを共有し、共同作業を行うにはどうすればよいのだろうか。匿名化は信頼性に欠ける一方、暗号化はデータの有用性を損なうとの見方もある。(出典)
そのため、実際のデータと同じ特性を持ちながら、特定のデータセットの関係者のプライバシーの必要性を尊重する金融データセットの合成方法を研究することが重要だ。「データに依存した新しい製品やサービスのイノベーションや構築をいかにして可能にするか」という問いの答えの一つとして注目されているのが、合成データの使用である。合成データとして合成された新しいサンプルは、実データの特性(フォーマットや分布)を実データと共有することができる一方、実データにマッピングすることはできないため、実データの使用に伴うリスクは伴わない。また、機械学習アルゴリズムをより効果的に訓練する上で必要となる実データではまれな例を増やすことができるため、AIアルゴリズム準備や意思決定をサポートできるという利点がある。
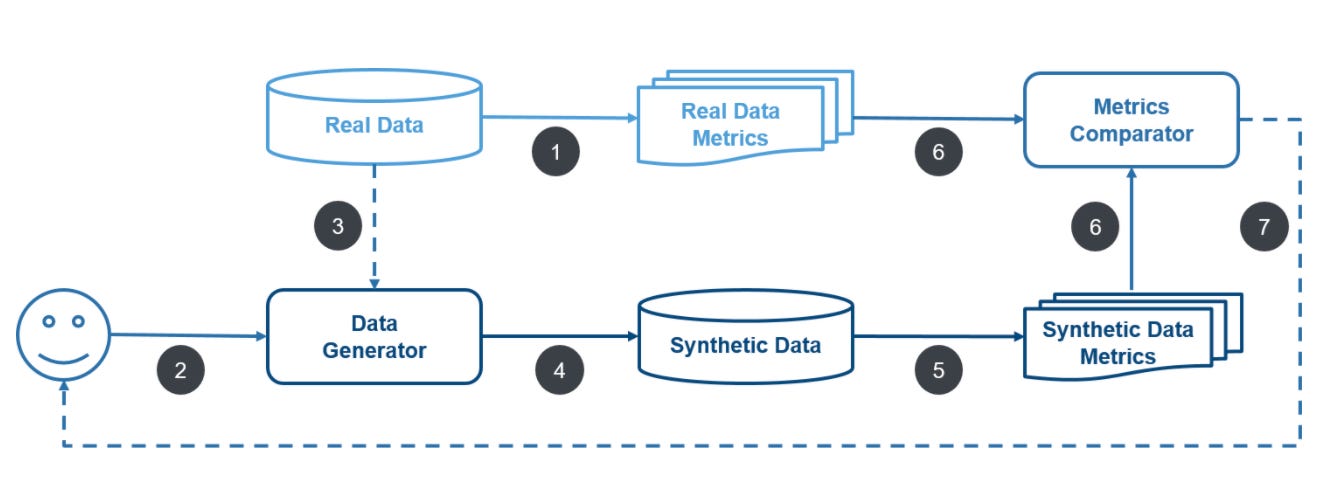
そこで、JP Morgan AI Researchでは、金融サービスにおけるAIの研究開発を促進するため、現実的な合成データセットを生成するための研究とアルゴリズム開発を行っている。以下は、JP Morgan AI Researchで考案された、合成金融データセットの生成プロセスである。(出所)
ステップ1:実データのメトリクスを計算する
ステップ2:Generatorを開発する(統計的手法やエージェントベースのシミュレーションの場合もある)
ステップ3:(オプション)実データを使ってGeneratorを補正する
ステップ4:合成データを生成するためにGeneratorを実行する
ステップ5:合成データのメトリクスを計算する
ステップ6:実データと合成データのメトリクスを比較する
ステップ7:(オプション)比較メトリクスを改善するためにGeneratorを改良する
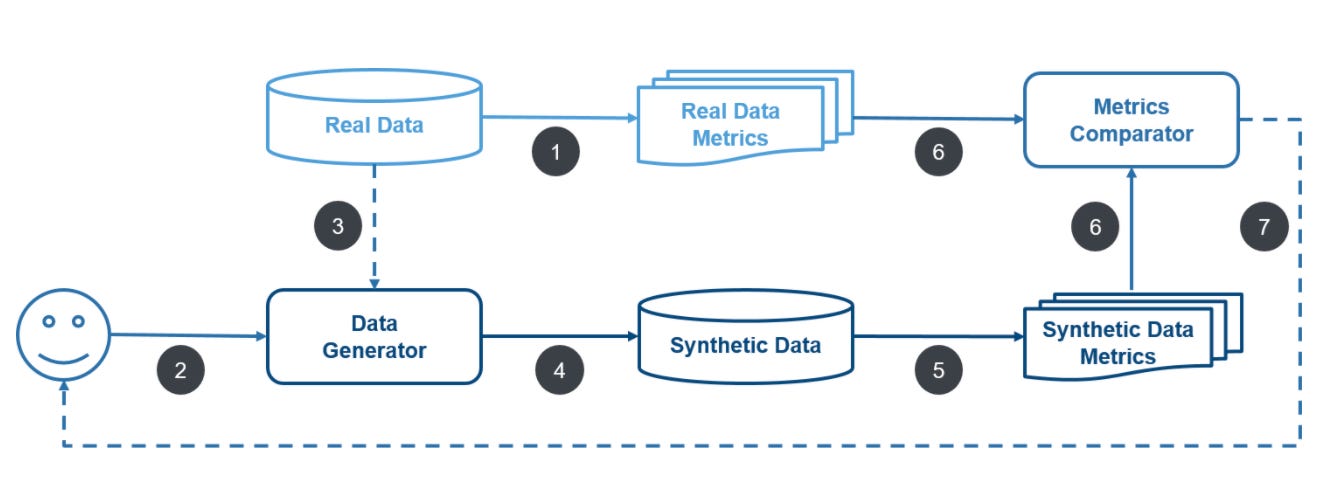
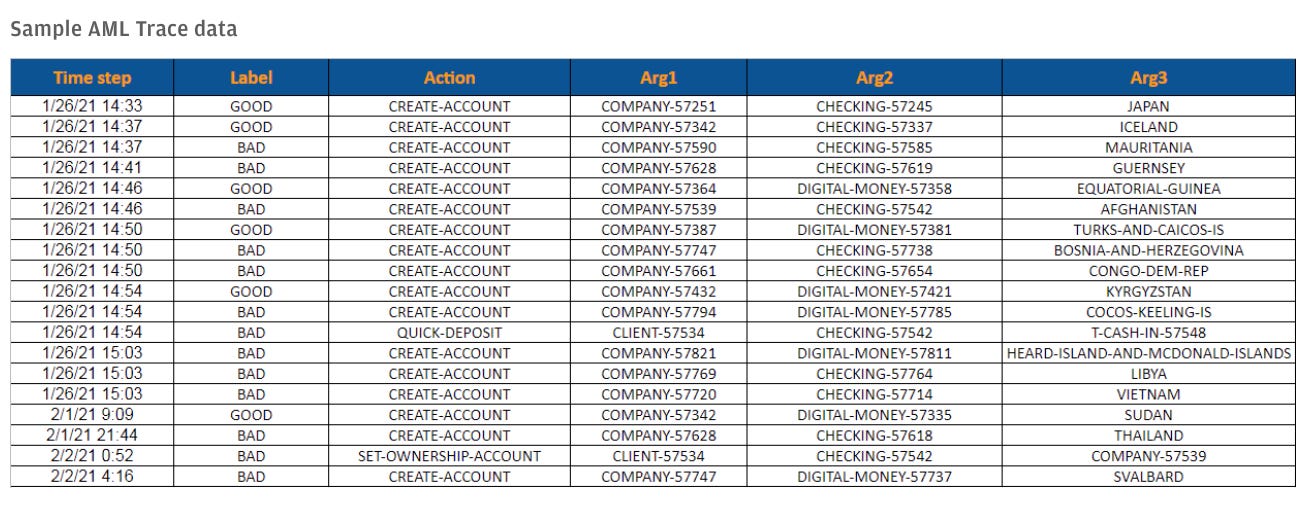
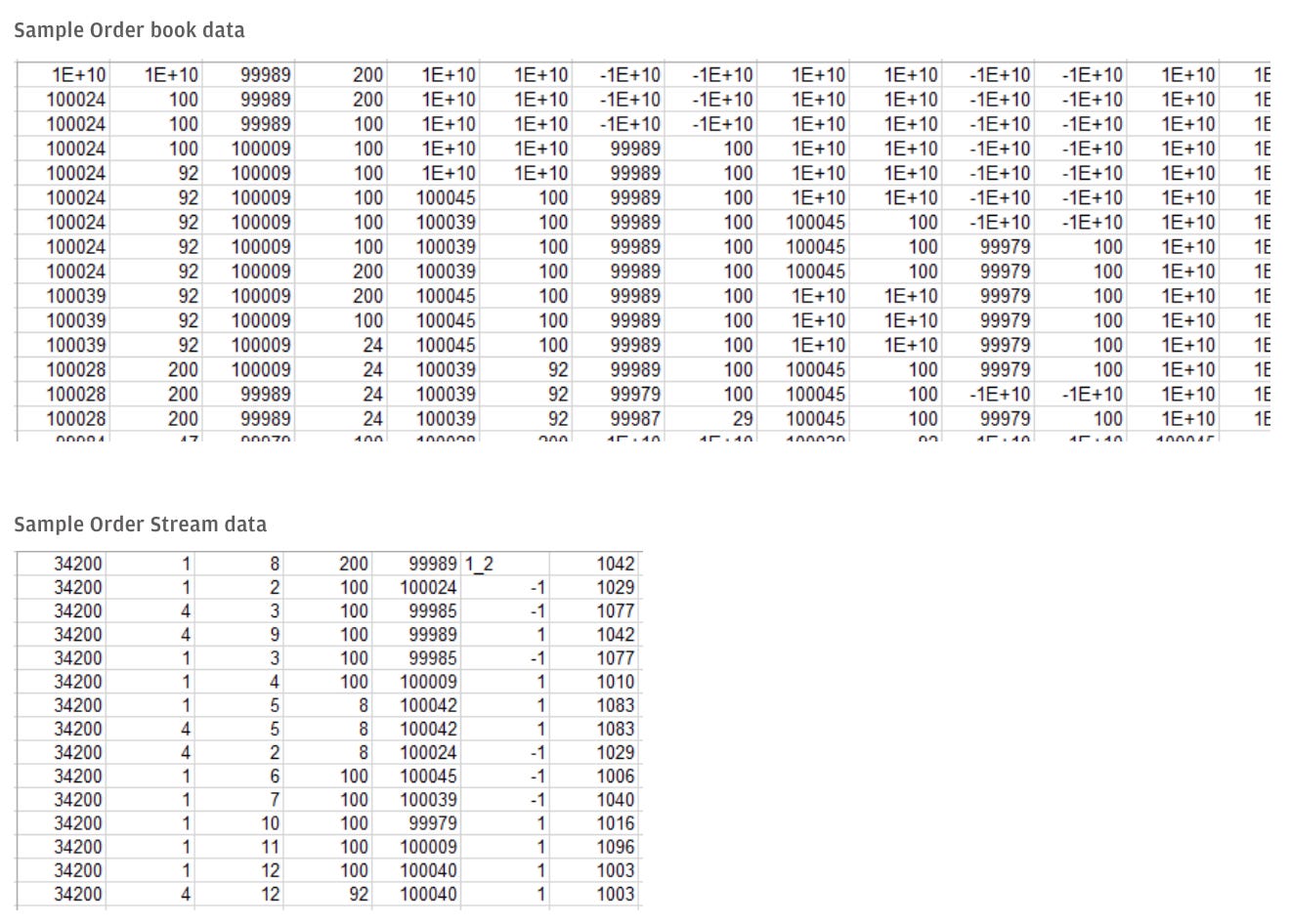
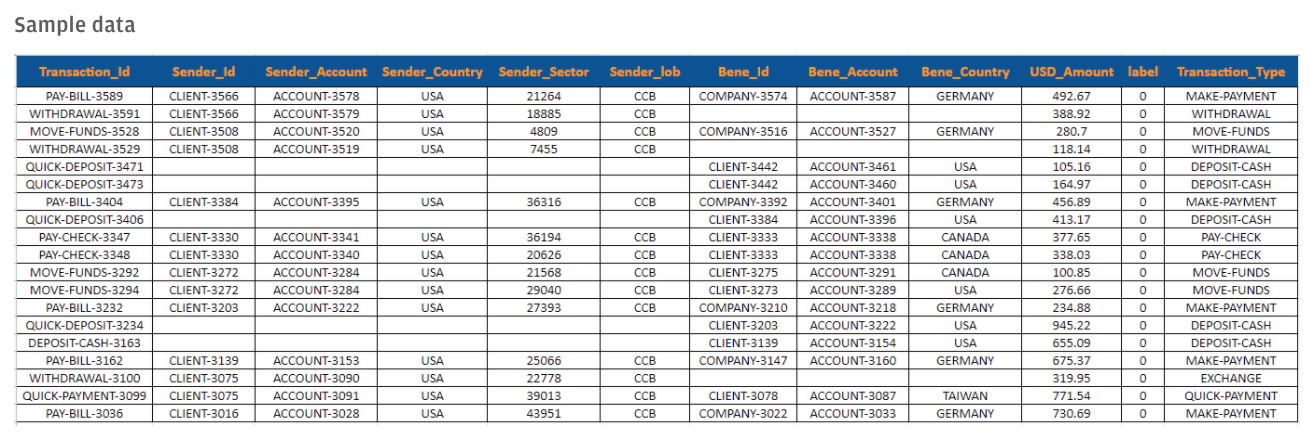
これらの技術を活用して、JP Morgan AI Researchが開発した合成データセットには、「AML」「カスタマージャーニーイベント」「マーケットの執行データ」「不正検知のための決済データ」がある。
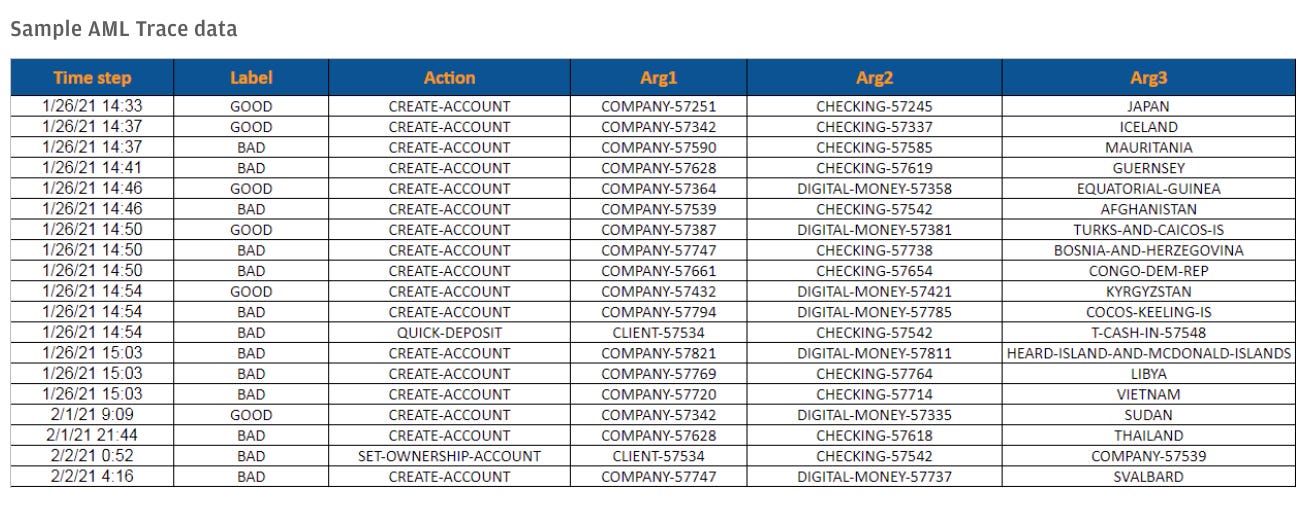
1つ目の「AML」のデータは、AI計画実行シミュレータを実行して生成されたものであり、合法的な顧客とマネーロンダリングに従事する顧客の、金融機関とのやり取りのシーケンスを表している。データには、銀行の顧客関連活動の状態と行動のペアが含まれており、例えば口座開設・取引・支払・引き出し・購入などがある。
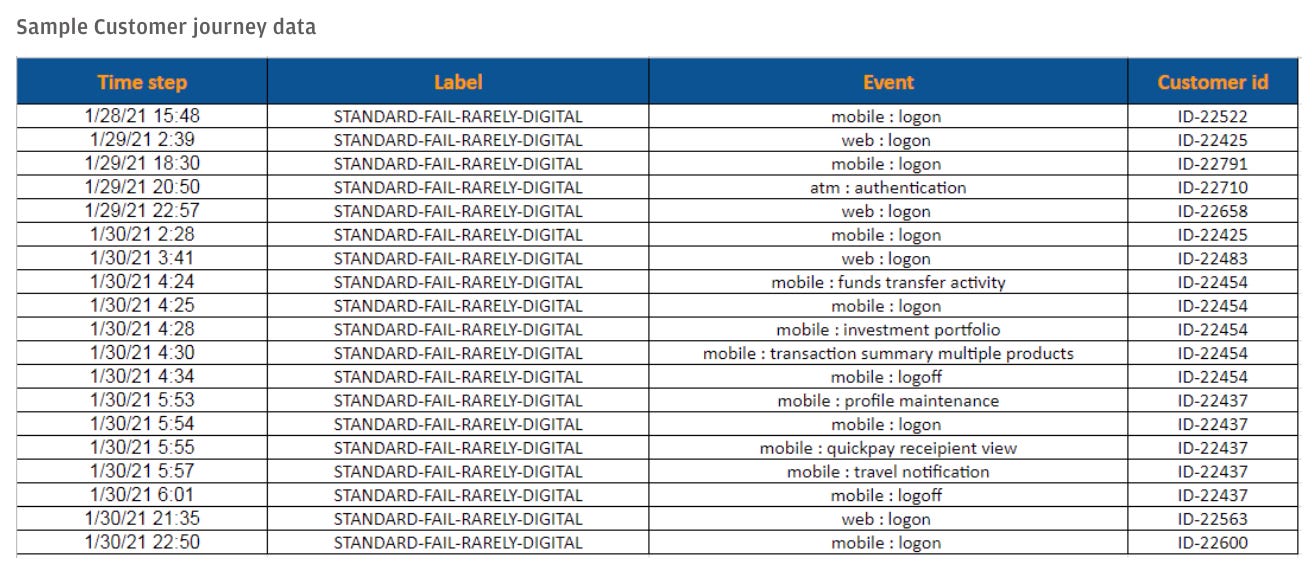
2つ目の「カスタマージャーニーイベント」のデータは、AI計画実行シミュレータを実行し、出力された計画を表形式に変換することで生成されたものであり、リテールバンキングを利用する顧客と銀行とのやり取りを表すシーケンスを表している。イベントの例としては、Webアプリケーションへのログイン・支払い・ATMからの引き出しなどがある。
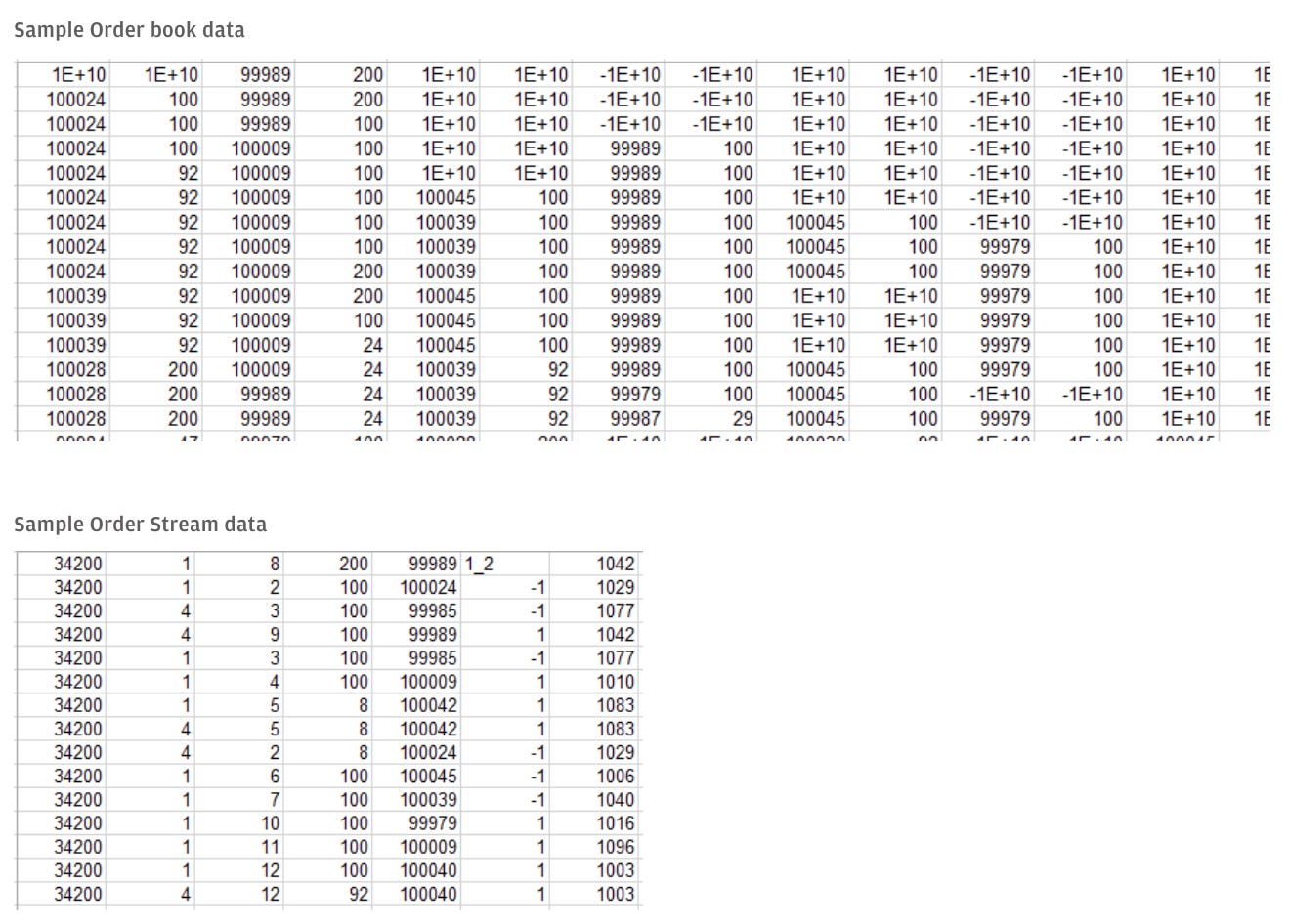
3つ目の「マーケットの執行データ」は、証券取引所の市場参加者による金融商品に関する一連の売買注文を記述した合成指値注文帳データである。具体的には、注文のメッセージやスナップショットを時系列で収録しており、流動性の高い銘柄について、異なる市場局面(例:上昇/下降トレンド、高/低ボラティリティ)におけるN取引日分のシミュレーションデータとなっている。
4つ目の「不正検知のための決済データ」は、AI計画実行シミュレータを実行し、出力された計画トレースを表形式に変換することで生成されたものであり、不正な取引を特定することを目的とした、対象者中心の視点で取引を表すデータである。このデータには、通常の取引だけでなく、事前に設定された確率で導入された異常な取引や不正な取引など、多種多様な取引が含まれている。また、データ生成モデルのパラメータには、クライアントの数・時間・不正行為の確率が含まれている。

銀行業務デジタル化と合成データ利用については、規制上の制約やデータ保護、従業員によるデータの悪用などのストレスを感じる必要を低減することによって、FinTech企業とのコラボレーションのためのデータを、国境を越えて配布可能になることや、データ提供の平均期間がを短縮できることによるデータPoCの迅速化などを期待する向きもある。(出典:”How Does Synthetic Data Help in Banking?”)銀行業務における今後の合成データ活用の方向性を引きつづき注視したい。(文責・畑島)

●合成データの利用において注意すべきこと
データは、企業の高度な分析や機械学習を推進する上で欠かせないが、プライバシーの問題やプロセス上の問題から、利用者が必要なデータを手に入れることは必ずしも容易ではない。
そこで、新たな手段として期待されているのが、合成データである。
合成データとは、実際のデータセットで訓練されたAIアルゴリズムによって人工的に生成されたデータのことを指す。
合成データは、元のデータの統計量を維持するが、一部のデータを丸めたり削除したりするのではなく、データを完全に新たな実在しないデータに置き換える。
その目的は、既存のデータセットの確率分布をモデル化し、それをサンプリングすることで、統計的な特性やパターンを再現することにある。
重要なことは、アルゴリズムと作成された合成データのどちらからも、元のデータ(個人を特定できるような情報)を復元することは事実上不可能な点である。
合成データの実用化の例として、米国の国立衛生研究所(NIH)は、Syntegra社の合成データエンジンを使って、COVID-19患者記録データベースの個人を特定できないレプリカを生成している。
このデータベースには、270万人以上のスクリーニング対象者と41万3,000人以上のCOVID-19陽性患者が含まれている。
この合成データセットは、元のデータセットの統計的特性を正確に再現しているが、元の情報へのリンクは無いため、世界中の研究者が共有して利用することができ、この病気についての知識を深め、治療法やワクチンの開発を加速させることができる。
医療以外の分野でも、データの使用や顧客のプライバシーに関する規制が特に厳しい金融サービス業界では、データプライバシー規制に抵触することなく、データを利活用するために合成データを利用できる。
また、小売業者は、個人情報を開示せずに顧客の購買行動に関する合成データを販売することによって、新たな収益源となる可能性を見出している。
事業にとっての合成データの利点は、重要なデータを公開・共有しつつも、企業や顧客のプライバシーやセキュリティを損なうリスクを排除できることである。
暗号化・匿名化・高度なプライバシー保護(例えば、準同型暗号化やsMPC)などの技術は、元のデータと、そのデータに含まれる個人にたどり着く可能性のある情報を保護することに重点を置いているものの、元のデータが存在する限り、何らかの形でデータが漏洩したり暴露されたりするリスクは常に存在してしまう。
これに対して、合成データを利用することによって、プライバシー・セキュリティに関する時間のかかる手続きが不要になるため、企業はより迅速にデータにアクセスすることができるようになる。
たとえば、ある金融機関では、意思決定者がビジネス上の問題を解決するのに役立つ豊富なデータを保有していたが、非常に高度に保護されており、純粋な内部利用であってもデータにアクセスするのは大変な作業であった。
あるケースでは、少量のデータを入手するのに6カ月、更新情報を受け取るのにさらに6カ月を要した。
それが今では、元のデータを基に合成データを生成しているため、継続的にデータを更新してモデル化し、ビジネスパフォーマンスを向上させるための継続的な洞察を得ることができている。
このように魔法のように思える合成データも、実用化においては様々な課題が存在している。
合成データの作成は非常に複雑なプロセスであり、適切に行うためには、単にAIツールを導入してデータセットを分析するだけでは不十分である。
合成データを活用するためには、専門的なスキルを持ち、AIに関する高度な知識を持つ人材が必要となる。
さらに合成データの評価は、さまざまなユースケースがあるため複雑になっており、予測や統計分析など、異なるタスクには特定の種類の合成データが必要であり、それらには異なる性能指標、要件、プライバシーの制約が伴う。
さらに、データモダリティ(様相)が異なれば、独自の要件や課題が出てくる。
例えば、日付と場所を含むデータを評価しているとする。
これらの2つの離散的な変数は、それぞれ異なる方法で動作し、それらを追跡するために異なる測定基準を必要とする。
また、多くの企業では、文化的な抵抗感が合成データの概念を妨げている。
具体的には「自社では使えない」「信用できない、安全ではなさそう」「規制当局は決して賛成しないだろう」などの懸念がブレーキをかけている。
合成データを採用するには、経営幹部、リスクチーム、法務チームを巻き込み、合成データの安全性、有効性を納得させることが重要となる。
この上で、 合成データの信憑性を証明すること、つまり「作成した合成データが本当に元のデータを表していること」を証明する必要がある。
ただし、元のデータセットとは一切関係なく、また元のデータセットを公開することもできないため、とても難しい。
正確に一致しなければ、合成データセットは真に有効ではなく、多くの潜在的な問題が発生する。
例えば、新製品の開発のために合成データを作成したとする。
もし、合成データセットが元の顧客のデータセットを忠実に表していなければ、顧客が何に興味を持っているのか、何を買いたいと思っているのかについて、誤った購買シグナルが含まれている可能性がある。
その結果、誰も欲しがらない製品を作るために、多額の費用を費やすことになるかもしれない。
さらに不適切な合成データを作成した場合、企業は規制当局と対立することになる。
このようなデータを使用して、誰かに害を与えたり、宣伝通りに機能しない製品を作ったりするなど、コンプライアンスや法的な問題が発生した場合には、多額の金銭的なペナルティが課せられ、場合によっては将来的に厳しい審査を受けることになる可能性もある。
規制当局は、合成データがどのように作成され、測定され、共有されるのかを評価し始めたところであり、この取り組みを導く役割を果たすことは間違いない。
また、合成データが不適切に作成された場合には、「メンバーシップ推論攻撃」と呼ばれる攻撃を受ける可能性がある。
機械学習モデルは、未知のインプットに比べて訓練データでより良い性能を発揮する。
メンバーシップ推論攻撃は、この特性を利用して、機械学習モデルの学習に使用された例を発見または再構築する。
攻撃者は必ずしも対象となる機械学習モデルの内部パラメータに関する知識を持っている必要はない。
モデルのアルゴリズムとアーキテクチャ(SVM、ニューラルネットワークなど)、またはモデルの作成に使用されたサービスのみの知識で攻撃が可能。
対象となるモデルが機密情報に基づいて学習されている場合に、セキュリティやプライバシーの問題を引き起こす可能性がある。
実際、2017年の「IEEE Symposium on Security and Privacy」では、コーネル大学の研究者が、主要なクラウドベースの機械学習サービスすべてで動作するメンバーシップ推論攻撃手法を提案した。(参照)
合成データのコンセプトは、元のデータとは何の関係もないということだが、合成データが正確に作成されていない場合には、悪意のあるアクターは、あるデータポイントを元のデータセットにさかのぼって追跡し、特定の人物が誰であるかを推論できる脆弱性を見つけることができる可能性がある。
悪意のあるアクターは、この知識を利用して、合成データセットを継続的に調査したり質問したりして、最終的に残りのデータを把握し、元のデータセット全体を公開することができる。
技術的には非常に難しいことだが、適切なリソースがあれば不可能ではなく、もし成功すれば、その影響は甚大なものになる。
合成データが自社にとって意味のあるものかどうかを検討する上で、企業は以下の点について注意する必要がある。
ステークホルダーを巻き込む。
合成データは、ほとんどの人にとって新しくて複雑な概念である。
合成データプログラムを展開する前に、「合成データとは何か、どのように使用するのか、企業にどのような利益をもたらすのか」を、経営陣・リスクチーム・法務チーム全員が十分に理解することが重要となる。
必要なスキルを身につける。
合成データの作成は非常に複雑なプロセスであるため、企業はデータサイエンティストやエンジニアが合成データの作成方法を習得できるかどうかを判断する必要がある。
また、どのくらいの頻度で合成データを作成するのかを検討する必要がある。それによって、時間と費用をかけて合成データ作成機能を構築するか、必要に応じて外部の専門家と契約するかが決まる。
目的を明確にする。
合成データは、特定の目的を念頭に置いて作成する必要がある。
その目的によって、合成データの作成方法や、元のデータのどの特性を維持するかが変わる。
また、合成データを販売して新たな収益源とする可能性がある場合には、その新たなビジネスモデルを計画することが重要。
合成データはデータサイエンスの最先端に位置しているものの、現時点では多くの企業が合成データを現実のビジネス課題に適用する方法を試している段階にある。
プライバシーの保護やセキュリティを徹底しつつ、データの価値を最大化するためにもこのような技術の適切な利活用が推進されることを期待する。(文責:野畑)
LayerX Labsでは、次世代プライバシー保護・セキュリティ技術Anonifyの正式提供に向けトライアルパートナーの募集を開始、合わせて公式ウェブサイトを公開しました。

「Anonify」の公式ウェブサイトはこちら
「Anonify for Insurance」ホワイトペーパーはこちら
LayerXではエンタープライズ向けブロックチェーン基盤を基本設計、プライバシーの観点から比較したレポートを執筆し、公開しています。
基本編のダウンロードはこちら
プライバシー編ダウンロードはこちら
Section2: ListUp
1. プライバシー・セキュリティ
●差分プライバシーに対するユーザーのプライバシー期待の調査
ユーザーが差分プライバシーをどのように考えているかについてはほとんど知られていないとして、(1)ユーザが差分プライバシーによる保護を気にしているか、(2)そのために差分プライバシーシステムとデータを共有することに積極的であるかを調査したもの。
調査(n=2424)の結果、ユーザーは、差分プライバシーによって保護される情報漏洩の種類を気にかけており、これらの漏洩のリスクが起こりにくい場合には、個人情報を共有することに積極的であることがわかった。
さらに、差分プライバシーが一般的に説明されている方法は、ユーザーのプライバシーに関する期待を無造作に設定するものであるものとして、展開によっては誤解を招く可能性があることがわかったとのこと。
これらの結果を総合して、ユーザーが差分プライバシーシステムで情報を共有しようとする意思を理解するためのフレームワークとして、ユーザーの事前のプライバシー懸念と差分プライバシーの説明方法との間の相互作用を考慮することを提案している。
https://arxiv.org/abs/2110.06452
●エアバス社、衛星画像の処理に合成データを活用して新サービスへの対応を迅速化
地球観測画像を解析するための仮想的な合成データセットを作成するプラットフォームを提供するOneView社とのパイロットプロジェクトを通じて。合成データの有効性を検証している。
衛星画像サービスの利用者には、必要に応じて建物や道路を抽出する都市計画担当者、線路を侵食する植物を検知する鉄道会社、主要ショッピングモールの前で自家用車の数や位置を測定する小売業の専門家、危機的状況下で航空機を捜索する軍事防衛サービスなどがある。
合成データを使用した結果と実データを使用した結果を比較して、アプローチを検証することができると考えたとのこと。
3つのトレーニングデータセットを作成。
「ベンチマーク用の実写画像」「OneViewから100%生成されたトレーニングデータセット」そして「95%の合成データと5%の実写データを組み合わせたもの」を用いて、82,000枚の航空機の合成画像と3,000枚の実写画像を含むデータセットを作成。
その結果、混合データセットでは、エアバス社が実データで経験していたものよりも20%の改善が見られたとのこと。
●総務省|郵便局データの活用とプライバシー保護の在り方に関する検討会(第1回)配付資料
https://www.soumu.go.jp/main_sosiki/kenkyu/postaldata_privacy/ryutsu14_01.html
●Zホールディングス、「グローバルなデータガバナンスに関する特別委員会」最終報告
https://www.z-holdings.co.jp/notice/20211018
●「経済安保の配慮足りず」「韓国色を隠す意向あった」、LINE問題の最終報告書が公開| 日経クロステック/日経コンピュータ
https://xtech.nikkei.com/atcl/nxt/column/18/00001/06160/?n_cid=nbpnxt_twbn
●銀行業務デジタル化と合成データ利用について。
異常・レアなインシデント・不正行為を検知するモデルの性能強化
銀行の不正検知モデルは、正しいデータで学習されて初めて正常に機能するもの。
合成データセットは、適応性があり、更新が簡単で、安全であるため、機械学習モデルを必要に応じて頻繁にチューニングできる。
実際のデータを利用する場合と比べ、合成データでは不正検知モデルの性能が2~15%向上。
誤検知の2%減少は、調査業務における数百万ドルの節約に資する。
コラボレーションの促進
規制上の制約やデータ保護、従業員によるデータの悪用などのストレスを感じる必要がないため、FinTech企業とのコラボレーションのためのデータを、国境を越えて配布可能になる。
データPoCの迅速化
現実的で安全な合成データを搭載したサンドボックスは、ベンダーのコストとリスクを最小限に抑え、イノベーションと製品開発を加速する。
合成データは、本番データよりも安全性が高く、統計的に同等で、適応性の高い代替品となる。
ベンダーが簡単にアクセスできるため、データが安全に管理された環境でソューションをテストすることができる。
データ提供の平均期間が「6ヶ月〜18ヶ月」から「3週間」に短縮できた。
PoCの平均コストは80%減少し、年間1000万ドル以上の節約効果がある。
https://technofaq.org/posts/2021/10/how-does-synthetic-data-help-in-banking/
●Siemens、自律走行車むけに合成データを生成し、環境全体をモデル化するスタートアップを設立
自律走行車や産業オートメーションにおける機械学習システムのシミュレーションを行うため、Simulytic社を設立
信頼性の高い合成データを用いて、自律型モビリティの大規模展開を加速することに注力するもの
これによって、事故の発生確率、変化する交通の流れや渋滞パターン、天候や道路状況の影響、その他多くの地域的要因について、競争力のある包括的かつ独立した評価を行うことができる。
また、模擬運転データのライブラリを構築し、それを現実世界の運転活動で補強することによって、複雑でダイナミックなリスク環境を理解するために必要なデータを保険会社などの企業に提供することが可能に。
このモデルには、自動車、歩行者、自転車などの代表的な交通構成要素と、交通標識、信号機、道路標示などの実際のインフラ要素が含まれている。すべての静的および動的要素は、速度、交通規則の遵守度、標識やマーキングの質、天候など、その場所で見られる実際のさまざまな状況に応じて変化させることができるほか、配置場所の種類に応じて、意味のあるエッジケースや複雑なシナリオも生成できる。
https://www.eenewseurope.com/news/siemens-launches-autonomous-driving-digital-twin-startup
●Immutaによる差分プライバシー解説記事
https://www.immuta.com/articles/understanding-differential-data-privacy/
●スタンフォード大のDan Boneh先生の暗号応用の修士コースの教科書(900ページ)
A Graduate Course in Applied Cryptography, Dan Boneh and Victor Shoup, Version 0.5, Jan 2020
https://toc.cryptobook.us/book.pdf
●総務省|プライバシーガバナンスに関するアンケート結果(速報版)の公表
https://www.soumu.go.jp/main_content/000773834.pdf
●MIT Sloan Management Reviewで「The Real Deal About Synthetic Data(合成データの真実の姿)」記事
https://sloanreview.mit.edu/article/the-real-deal-about-synthetic-data/
●医療は本当に「ゆりかごから墓場まで」を目指せるか
「次世代医療基盤法で医療情報の利活用はある程度進んだが、さらに一歩踏み込む必要がある」と話す。
例えば、医師ががん患者に手術をしたケース。手術後、長期にわたって治療経過や治療薬の効果を追いかけ、この経過をもとに5年生存率などを分析し論文を執筆する。
だが手術を施した医療機関の手を離れ、転院や自宅療養となった場合、肝心の患者の死亡情報や生存情報を把握するのは難しく、生存率が高まったのかどうかの結論を出すことができない。
該当患者の生存の有無などの情報は誰に聞けば良いのか――。それぞれの地方自治体が死亡情報などを持つものの、開示を求めても提供を拒否されるケースが多い。その根拠となっているのが、個人情報関連の条例だ。
https://business.nikkei.com/atcl/gen/19/00356/102000016/?ST=ch_dx
●官邸|第4回 健康・医療データ利活用基盤協議会 議事次第
全ゲノム解析結果等の患者還元及び研究開発向け利活用について
データ利活用プラットフォームの提供サービスについて
データプラットフォームにおいて利活用可能となるゲノムデータの全体像
https://www.kantei.go.jp/jp/singi/kenkouiryou/data_rikatsuyou/dai4/gijisidai.html
●平和堂とシルタス、購買データをヘルスケアに活用する実証実験を開始
SIRU+は、スーパーマーケットのポイントカードなどに紐付く購買履歴から栄養の偏りを可視化し、栄養バランスが整う食材やレシピをオススメするアプリだ。
来店者はアプリを介して栄養アドバイスをうけることができ、スーパーマーケットは来店者の健康ニーズにマッチした食の提案ができる。
https://www.poitan.jp/archives/86862
●米オリンパスへのサイバー攻撃は米制裁対象のロシア製ランサムウェアグループと関連か
https://jp.techcrunch.com/2021/10/22/2021-10-20-olympus-americas-ransomware-evil-corp/
●第92号 - NII Today / 国立情報学研究所
いま、あらゆる組織に求められているのが「プライバシーガバナンス」である。これまで、学術研究機関などが学術研究目的で個人情報を取り扱う場合、現行法において各種義務の適用除外としていたが、2021年に成立した改正法において学術研究に関わる適用除外規定の見直し(精緻化)がなされた。今後、学術研究機関においてもプライバシーガバナンスの体制構築の強化は必須と言えるだろう。
本特集では、学術研究におけるプライバシー保護に焦点を当てながら、改正個人情報保護法について解説するとともに、本来、プライバシーを守るために何に留意をすべきなのか、そのためにどのようなガバナンス体制の構築が必要なのか、またこの課題に情報学および国立情報学研究所(NII)がどう貢献できるのか、考察する。
プライバシーを守るということ〜学術研究にデータ安全管理の視点を|宍戸 常寿
改正個人情報保護法においてアカデミアに求められること〜信頼のもとで学術研究を進めるために|佐藤 一郎
ガバナンス体制強化で競争力を〜「企業のプライバシーガバナンスガイドブック」に学ぶ
学術研究分野における個人情報保護と外国のデータ保護法|板倉 陽一郎
https://www.nii.ac.jp/today/92/
●改正個人情報保護法、業界で分かれる対応 DX企業はどう受け止めているのか
https://www.itmedia.co.jp/business/articles/2110/14/news141_2.html
2. 中銀デジタル通貨
●【挨拶】内田理事「CBDCが存在する、あるいは存在しない決済システムの将来像」(第2回中央銀行デジタル通貨に関する連絡協議会) : 日本銀行 Bank of Japan
思考実験として、「経済・社会のデジタル化が進む中でも、日本銀行が、今と同じ公共財(「現金」と「日銀当座預金」)のみを提供し続けるとしたら、何が起こるのか」を挙げている
“「発行しない」ということも大きな決断になってきています。そして、発行しないのであれば、どうやってデジタル社会にふさわしい決済システムを構築していくか、考えなければなりません。いずれにしても現状維持はありえません。”と結んでいる
https://www.boj.or.jp/announcements/press/koen_2021/ko211015a.htm/
●中央銀行デジタル通貨に関する日本銀行の取り組み
概念実証フェーズ1
概念実証フェーズ2
実証実験に関連する論点
https://www.boj.or.jp/announcements/release_2021/rel211015c.pdf
●デジタル人民元ウォレットの匿名性について。ウォレット開設にあたり、少額決済は電話番号認証、少額決済以外も身分証明書の提出要とのこと
https://www.ledgerinsights.com/cbdc-digital-yuan-anonymity-china-digital-currency-leader/
●欧州Euroclear、フランス国債をCBDCで決済する実験レポートを発表
3. デジタル証券
●証券トークンを扱うPTSとして、SBIとSMBCグループによって設立されたODX(大阪デジタルエクスチェンジ)の第三者割当増資を引き受ける旨、野村・大和などが発表
https://www.nomuraholdings.com/jp/news/nr/holdings/20211015/20211015.pdf
4. 今週のLayerX
●LayerX SaaS事業 セールス&マーケティング最初の10人をまとめてみた
https://note.com/changun8/n/n6fa2e9ea691c
●入社60日でSalesforceを構築したSales Ops 立ち上げの話。|Fukutaro Matsumoto|note
“同じくらいSalesforce触れる人、ぜひ来て欲しい。あと、今のSalesforceに使いづらさを感じている人、ぜひ試して見て、ゴリゴリ受注して欲しい。”
https://note.com/fuku_taro_/n/ne2d5ee798805
●LayerXは柔軟な働き方ができる会社ですという話|福島良典 | LayerX|note
“育休に限らず、人生におけるライフイベントや、価値観、それに伴う働き方の多様さを担保していけるよう、日々LayerXの働き方ポリシーはアップデートしていくつもりです。”
https://note.com/fukkyy/n/nebf28879068a
●【オンライン会社説明会】LayerX事業紹介Night
LayerXの最新の事業状況やチーム、採用ポジションについて説明する会です。どなたでも参加可能です!
https://layerx.connpass.com/event/227604/
●元起業家視点から語るLayerXで働く良さ
"LayerXは全社として良い習慣や文化が浸透しており、1人ではうっかり忘れたりサボったりしそうなことを実践しやすい環境です。自分で起業していたときはダメダメだった自分でも少しずつ自分の血肉になっているのを感じています。"
https://note.com/zabeth129/n/n34b721959199
●オンラインイベント「コーポレート DX DAY」、お気軽にご参加ください!
https://prtimes.jp/main/html/rd/p/000000089.000036528.html
●LayerX の各ポジションについて、「ある一日の業務の流れ」「私達がやりたいけど出来ていないこと」がまとまっています。LayerXの様子を手触り感もって見て頂けると思います。たくさん空いてます!
https://herp.careers/v1/layerx
●LayerX、インサイドセールス始めたってよ|MJ_LayerX|note
“実はインバウンドを追い切れていませんでした。
数回の架電/メールで接続できなかったインバウンドリードが山のようにありました(マーケメンバーごめん)。ああ、メンバーさえいてくれれば・・・”
https://note.com/mj_layerx/n/n1bc00b1d2dc6
製品紹介・デモのご依頼に向けたお問い合わせは、こちらの「お問い合わせフォーム」よりお願いします
Disclaimers
This newsletter is not financial advice. So do your own research and due diligence.
